
A Distribution Management System for Relational Databases in Cloud Environments
2013-07-14 01:21:10SzeYaoLiChunMingChangYuanYuTsaiSethChenJonathanTsaiandWenLungTsai
Sze-Yao Li, Chun-Ming Chang, Yuan-Yu Tsai, Seth Chen, Jonathan Tsai, and Wen-Lung Tsai
1. Introduction
People rely more and more on information systems in their daily life with the development and integration of information and communication technologies. The incurred transactions and generated data have thus been increased dramatically. Cloud computing is one of the technologies developed sharing resources among tenants to improve system performance and to save operational cost. In addition to newly developed applications, legacy systems are also considered to transplant to cloud environments.
On a cloud platform, programs can be replicated to multiple nodes easily to distribute the processing load. This is achieved via the mechanism of virtual machine. To avoid becoming the next hot spot of processing, the database should also be distributed properly.
In order to handle huge amount of request for data processing, several key-value store systems, such as Google’s Bigtable[1], Yahoo’s PNUT[2], Amazon’s Dynamo[3], and other similar systems[4], have been developed. Data in these systems are replicated or partitioned across different servers so that the data store can be scaled in and out easily as needed. However, this kind of system tends to achieve system availability at the sacrifice of data consistency. This is known as the CAP (consistency,availability, and partition tolerance) theory[5]or PACELC[6].
Although systems with key-value store perform well in large-scale queries and simple updates, they can hardly provide ACID (atomic, consistent, isolated, and durable)guarantee for important database transactions[7]. For transaction processing systems with relational databases to run in the cloud environment, an effective tool is needed to help managing the partition and/or replication of data and providing ACID guarantee at the same time. With the aid of this tool, it may take less effort in migrating legacy systems to the cloud platforms. Moreover, professionals in relational database can be shifted and utilized with less training.
When distributing data to different nodes, the decisions of how to spread data on those nodes affect the performance and complexity of succeeding query and update tasks significantly. Partitioning data to more nodes can distribute the workload at the cost of increased complexity in data allocation, result integration, and transaction coordination. On the other hand, although replicating data to different nodes makes the system affordable to large amount of similar queries,synchronization among data nodes for data modification becomes a problem to ensure consistency. Since the transaction behavior of various applications differs from each other, it is important to partition or replicate data according to the characteristics of an application system such that better performance can be achieved.
This paper proposes a transaction-based database partition system for relational databases, which is named as database distribution manager (DBDM). The proposed DBDM has two basic modules which provide database partition and data migration functionalities, respectively.The database partition module advises strategies pointing out whether a table in a database should be partitioned or replicated, and transferred to which nodes. The algorithm in this module provides solutions according to behaviors of the application system, including content and frequency of each transaction, tables used in each structured query language (SQL) statement, and relations among tables in the database. In principle, decisions made by this module let tables use in a single SQL statement together so that join operations can be accomplished within one node. This will avoid massive data movement among nodes.
The data migration module, in turn, actually moves data according to the difference between current data distribution and the proposed one. The migration can be scheduled in a progressive manner by moving a limited amount of data at a time. In this way, the number of interferences to the operation of the system can be reduced.The amounts of data to be moved in one step and the time interval between two consecutive steps are set as parameters to the migration module.
The proposed system was implemented to verify its feasibility. Preliminary experiments show that the database is effectively distributed and tables are grouped according to transactions of the application system. Further experiments will be conducted to verify the effectiveness on load distribution and performance enhancement.
In the following, related works are discussed in the next section. The proposed system is introduced in Section 3.Section 4 illustrates the implementations and some design issues are discussed. Section 5 concludes this paper.
2. Related Works
In recent researches in database partition, Rao et al.devised a tool named DB2 design advisor to automatically select optimal solution for data partitioning[8],[9]. This tool used workload as input and suggested a method of distribution in four facets, namely, indexing, materialized view, database partition, and multi-table clustering. To take into account of the dependency among them, the authors designed a hybrid method to reduce execution time without degrading system quality. These methods took advantage of parallelism and were suitable for applications involving analysis of massive data such as data warehousing and mining. However, it is hard to do parallel transactions due to the locking and synchronization problems incurred by the ACID requirements.
Agrawal et al. proposed a technique for automatic partitioning database horizontally and vertically[10]. The technique was also implemented and tested on Microsoft SQL Server. Although system performance and manageability factors were considered, their method was only focused on a single node. Extending their algorithm for partition with multiple nodes needs more efforts.
NewSQL was proposed by several researchers for on-line transaction processing (OLTP)[11]. The purpose of NewSQL is to distribute the workload while still guaranteeing the ACID requirements. The efforts are principally focused on searching for an optimal execution plan for data inquiry and manipulation. As mentioned in the previous section, the efficiency of statement execution depends on how the data are distributed. Thus, a good partition strategy is the basis of efficient query execution.
Some researches discussed data lookup problems in query processing[12],[13]. Improvements were made on the synchronization protocol such that distributed transactions can be conducted more efficiently. However, these improvements also rely on proper distribution of data to obtain maximal performance.
There were also researches working on server allocation after partitioning the database. Apers used a model to evaluate cost functions under different server configurations. Thus, how to distribute data among the servers can be decided with this model[14]. Genetic algorithm has also been adopted for the server allocation problem[15]. The researchers found that their algorithms outperformed greedy heuristics under several different partition sizes. Menon formulated the server allocation as an integer programming problem[16]. Storage and processing capabilities were considered as constraints to the objectives. In addition to the factors considered in these researches, current distribution of the database should also be taken into account since the difference between current status and the proposed distribution determines the amount of data movement, which will affect the system performance during the redistribution.
In summary, many factors should be considered in order to properly partition a database. These factors include the cost of ensuring ACID requirement, data migration for partitioning, storage and capacity of servers, server allocation, and data lookup and transmission to complete a query. In the database partition system proposed by this paper, transaction behavior and database relations are used to help judge the distribution strategy of data, such that the majority of factors can be taken into consideration. The architecture of the proposed system is introduced in the next section.
3. System Architecture
The architecture of the proposed DBDM is shown in Fig. 1 along with its operation environment. In this environment, DBDM is operated outside the distributed database management system (DBMS). It retrieves database schema and statistics of the application system,evaluates partition strategies, and migrates data among data nodes according to the partition decision. Distributed database (DB) administrator can monitor the current partition status from the interface. The administrator can also direct the behavior of partition and migration process by adjusting threshold values and/or parameters. Some of the system information, such as available servers and their capacities, are also set by the administrator.
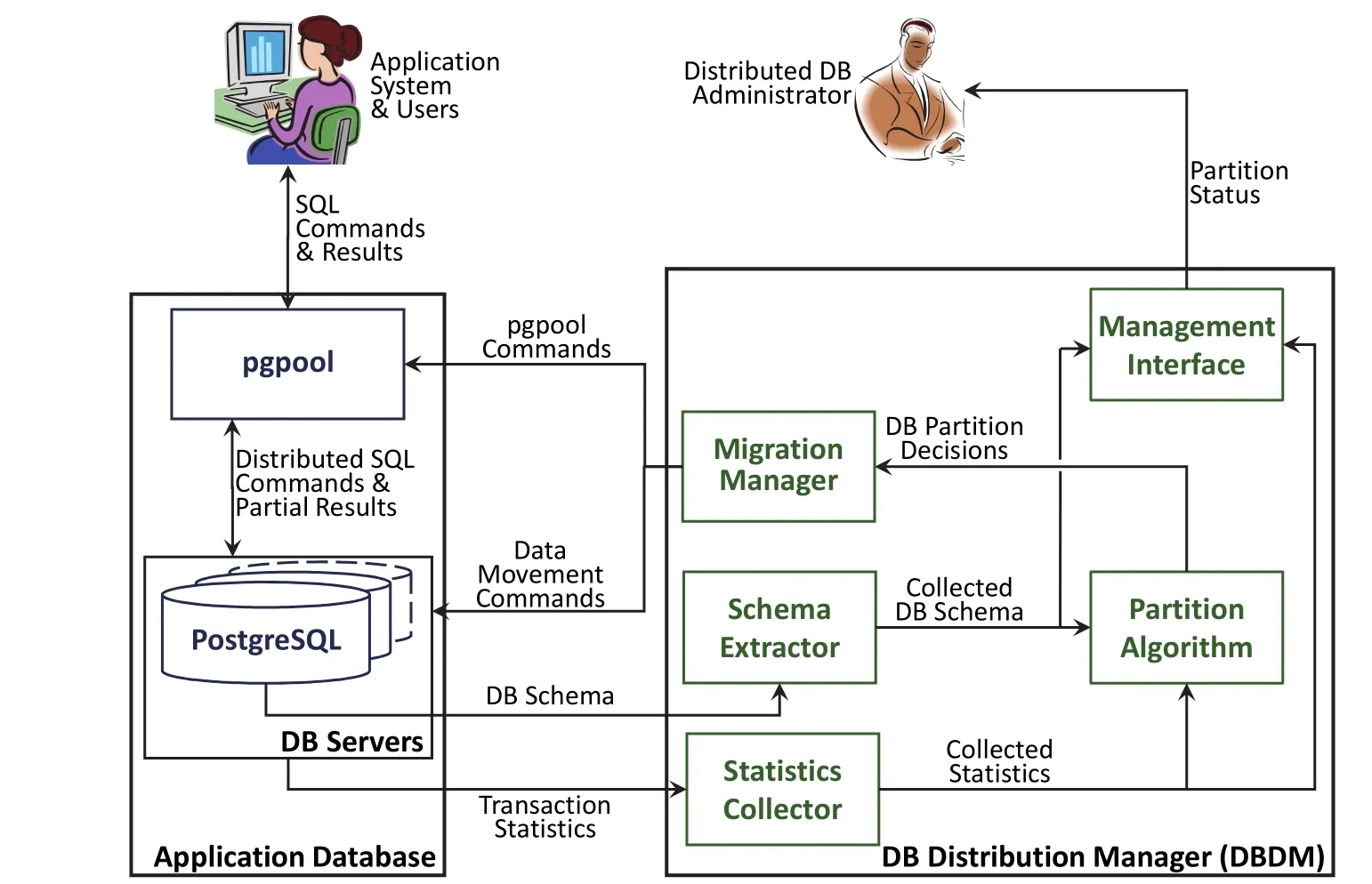
Fig. 1. System architecture of the database distribution manager.
Since this research focuses on database partition and migration, PostgreSQL DBMS and pgpool, both developed by PostgreSQL Global Development Group, are used as the distribution DBMS to simplify the setup of experiment environment. The proposed DBDM can be used with other distributed DBMS as well by modifying the interfaces between DBDM and the target distributed DBMS.
The DBDM comprises five modules. The “Partition Algorithm” module performs the evaluation of current database status and the proposition of partition strategy.The “Migration Manager” module then actually moves records in the database in response to the proposed partition strategy. Two types of information are needed for these two modules to complete their missions. The static information of the database, such as table schema and relationships among tables, are provided by the “Schema Extractor”module. The “Statistics Collector” module in turn gathers the runtime information, for example, the number of records and distribution of key values. Finally, the“Management Interface” module is in charge of the communication with the administrator.
The two main functionalities of DBDM, which are the“Partition Algorithm” and the “Migration Manager”, are introduced in more detail next.
3.1 Partition Algorithm
The objective of the “Partition Algorithm” module is maximizing system performance under the constraint of guaranteeing the ACID requirement. System performance is in turn affected by transaction processing time and the workload. Thus, the procedure and characteristics of handling a transaction are analyzed first so that the algorithm can be tailored for the requirements of transaction processing.
The steps to process a distributed transaction are 1)parsing, 2) execution planning and optimizing, 3)distributed command dispatching, 4) result collecting and summarizing, and 5) distributed transaction committing.The operation analysis is focused on those steps which are related to the distributed process, namely, data allocation,data transmission, and distributed transaction commitment.
Consider the data allocation process first. Two methods are generally used in partitioning and locating the records in a table. One method is for storing and retrieving data according to a hash function of the key. The advantage of this method is its constant time for locating data. However,it is hard to find a suitable hash function for partitioning data in irregular sizes. The other method is for dividing the table into consecutive pieces according to the key.Although it suffers from increased data locating time as the number of partitions increases, this method can partition data in arbitrary lengths. Since the distribution of key values in a table depends on the characteristics of the application and is not predictable, the tables are divided into consecutive segments in this research.
Next, the data transmission among data nodes is discussed. The most time-consuming part in a query is the join operation, which includes cross product operations.Although the final result may be few, the amount of intermediate data is large due to the cross products.Massive data transmission will be inevitable if tables involved in a join operation reside in different nodes.Conversely, the transmission of the query results only is necessary if those tables are stored in the same node.Therefore, the “Partition Algorithm” module should strive to put together tables within the same query statement.
Finally, distributed transaction commitment needs synchronization among data nodes which participate in the transaction to guarantee the ACID requirements. Due to the data transmission problem, keeping tables of the same transaction together can effectively reduce the communications among nodes.
Two strategies of database partitioning can be concluded from the above discussions. First, the tables involved in the same query statement should be kept together so that massive data transmission among nodes can be avoided. Next, the table is divided consecutively if partitioning is inevitable.
However, grouping tables together makes data centralized instead of distributed. The group itself should be divided if it becomes the transaction hot spot. To allow the partition of the group while keeping related tables together, replication and horizontal partitioning are used. In a group to be partitioned, the tables containing elementary information are replicated since they act as lookup tables and normally contain less data. Moreover, the tables with master-detail relationships are partitioned in pairs. For example, the table storing items of sales orders is partitioned according to how the table storing headers of sales orders is partitioned. In this way, data in a group is distributed over multiple nodes while those related records needed in join operations still keep intact.
After analyzing the behavior of transaction processing and its performance concerns, the “Partition Algorithm” is designed and its modular structure is depicted in Fig. 2. The algorithm is divided into three main modules with three supporting modules, respectively. The main modules,namely “Grouping Tables”, “Assign Servers to Groups”,and “Partition Horizontally”, perform the steps of database partition, whereas the supporting modules provide the needed information derived from outside and/or previous results.
Among the three main modules, the “Grouping Tables”module first inspects every SQL statement and puts tables together if they are involved in a join operation. Next, the“Assign Servers to Groups” module allocates servers for each group according to the transaction frequencies of the groups and the capabilities of the servers such that each server will get a portion of transaction load proportional to its capability. Finally, a group is partitioned horizontally into consecutive pieces by the last module if it is dispatched to more than one node.
3.2 Migration Manager
After the way of database partition is determined, the“Migration Manager” module will actually move those data to the proposed locations. This module includes three phases as shown in Fig. 3. The “Analyzing Differences”module takes current distribution of data and partition decisions generated by the “Partition Algorithm” module as its inputs. It compares each table in these inputs to determine the ranges of records which should be moved from one node to the other. Then, the “Calculate Amounts to Move” module evaluates the total amounts of data to be moved from one node to the other for every pair of nodes according to the analyzed differences. The migration action will be divided into several smaller movements if the system performance is concerned. As the last step, the“Move Data & Set Parameters” module composes physical instructions in response to the movement information passed from the previous step. The migration instructions are sent to each node involved in the migration process.The distributed DBMS is also informed regarding the changes on data distribution.
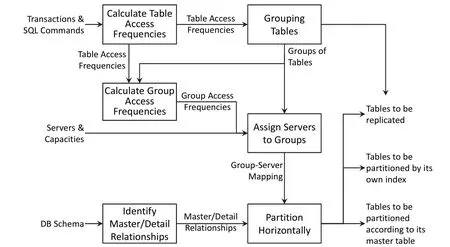
Fig. 2. Modular structure of the “Partition Algorithm”.
It is noteworthy that the system performance is affected by the selection, deletion, transmission, and insertion process during the migration. The effect on the performance varies with different operation environments.Thus, the same migration request which can be done in one shot may need to be executed progressively in a different environment. Moreover, the requirements in response time or system throughput which is tight to some applications may have wider tolerance in other systems.
To deal with this variety, the system leaves the decisions to the DB administrator by providing two parameters, namely, AmountInOneMove and IntervalBetweenTwoMoves. The former specifies the upper limit of data in one move. The later tells how much time the system should wait before the next movement can proceed.
The administrator can set AmountInOneMove to a small value and set IntervalBetweenTwoMoves to a large value so that the migration is hidden from the users. The drawback of this setting is that it takes a longer time to achieve the desired partition. This method is suitable for frequent redistribution since relatively few data are changed,which implies few data to migrate. In the other situation where the system might be running intermittently, the administrator can set AmountInOneMove to a huge number and run the partition and migration process in the periodical maintenance so that the migration can be done in the whole piece.
4. Implementations
This section introduces the results of physically implementing the proposed system. Some design issues are also discussed as a guideline for further research.
4.1 Implementation Results
The proposed system was implemented on Linux using PostgreSQL and pgpool as the distributed DBMS. Part of the transactions and data of a hospital’s inventory system were included as test data. Preliminary tests showed that the system partitioned the database and did the migration as expected. More data and queries are currently being prepared to further test the robustness and performance.
The original configuration of the system contains three nodes with the same computation power, and a forth node with 80% power of the previous nodes is added in the new configuration. A snapshot of the DBDM exhibiting the state of the database is shown in Fig. 4. The “current status”column describes the current distribution of the database,which may be either the previously calculated result or the status after several migration steps, depending on the migration strategy. The “objective distribution” column shows the newly suggested distribution obtained from the“Partition Algorithm”. The percentages in both columns represent the portion of the transaction load. The effect of adding a new node can be seen by comparing the “current status” and the “objective distribution” columns.
It can be observed that the distribution of table ITEM_EXCH has been changed due to different node configurations. The percentage of ITEM_EXCH allocated to sever are01 is different from the other since there are other groups of tables co-located on that node. The percentage of ITEM_EXCH on server are02 to server are04 in the “objective distribution” shows that they are indeed allocated by their respective capabilities.
4.2 Discussions
One of the strategies for the proposed “Partition Algorithm” is grouping together the tables related by join operations. However, almost all tables are related in a relational data model, which means that the grouping process may result in one group with all tables in most cases. Taking a closer examination on the relational data model, it is found that the tables which are most frequently joined are the ones storing basic information such as employee, department, product, and customer. These tables are usually served as referencing lists and contain relatively few records. Removing this kind of tables from the relational data model makes the remaining tables separate into smaller groups, which are really related in the application.
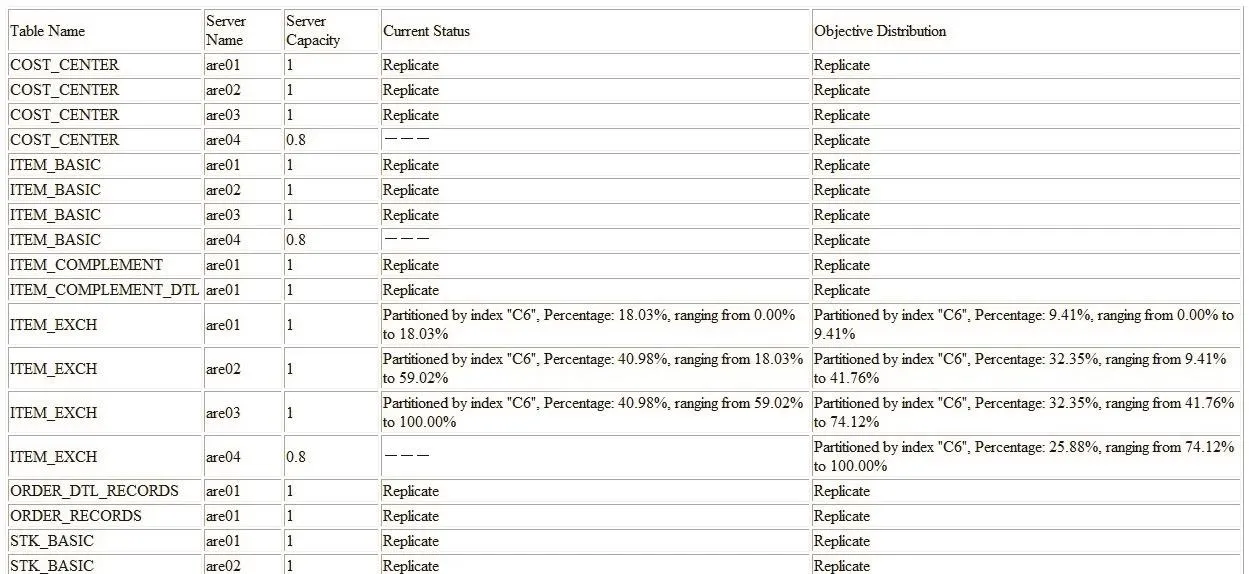
Fig. 4. Partial results of the implemented DRDM system.
According to the above observation, the system replicates the most frequently joined tables to the related groups while grouping the rest tables. In the current system,the frequency of joins involved is used to judge whether the table should be replicated or not. A parameter is introduced to indicate and adjust this frequency. Identifying those tables automatically is a possible direction in the future.
A second designing consideration is how to map transaction distributions into data distribution. To simplify the implementation, the proposed system assumes that each transaction accesses those records in a table evenly. This is obviously not the case in physical situations. For example,trains in peak hours are queried more often than others and undelivered sales orders are accessed more frequently than historical ones. To cope with this, various access patterns should be observed and recorded so that the “Partition Algorithm” can distribute the data in accordance with the transaction load.
Finally, the modular design is important to the flexibility of the proposed system. In the global view of the system architecture (see Fig. 1), the “Schema Extractor”and the “Statistics Collector” modules are separated from the partition and migration modules purposely, so that they can be replaced easily to adopt other DBMS as needed. The command generation process in the “Migration Manager”module (see Fig. 3) is also isolated for the same reason.
The transaction frequencies used in the “Partition Algorithm” module (see Fig. 2) is isolated from the steps of partition calculation. Furthermore, the unit of those figures is transformed to percentages. Through this arrangement,the transaction frequencies used for the partitions can be changed to other measures without affecting the algorithm.Conversely, the proposed architecture can be used as a platform to test different partition strategies by simply replacing the algorithm body.
5. Conclusions
In cloud environments, a transaction processing application needs to keep ACID guaranteeing and handle huge amount of data efficiently. Providing a partition strategy to the distributed database is important for fulfilling these requirements. This paper proposes a database distribution management system, DBDM, which distributes the data according to the transaction behaviors of the application system. It splits tables into groups so that join operations can be conducted in a group. Moreover,large groups are horizontally partitioned in pairs by observing the master-detail relationships between pairs of tables. These strategies avoid massive transmission of records in join operations among data nodes.
The proposed DBDM system was also implemented to verify its feasibility. Preliminary experiments showed that the DBDM performed the database partition and migration so that the transactions were distributed over the nodes.Extensive experiments will be conducted to evaluate the effectiveness on the performance improvements.
The DBDM system was modularly designed so that it can be easily adapted to different DBMS. Modules which deal with the “Partition Algorithm” can also be replaced to evaluate the performance of different algorithms.
[1] F. Chang, J. Dean, S. Ghemawat, et al., “Bigtable: a distributed storage system for structured data,” in Proc. of the 7th Symposium on Operating Systems Design and Implementation, Seattle, 2006, pp. 205-218.
[2] B. F. Cooper, R. Ramakrishnan, U. Srivastava, et al.,“PNUTS: Yahoo!’s hosted data serving platform,” in Proc.the 34th Int. Conf. on Very Large Data Bases, Auckland,2008, pp. 1277-1288.
[3] G. DeCandia, D, Hastorun, M, Jampani, et al., “Dynamo:Amazon’s highly available key-value store,” in Proc. of the 21st ACM SIGOPS Symposium on Operating System Principles, Stevenson, 2007, pp. 205-220.
[4] D. Agrawal, A. E. Abbadi, S. Antony, and S. Das, “Data management challenges in cloud computing infrastructures,”Lecture Notes in Computer Science, vol. 5999, pp. 1-10,2010.
[5] S. Gilbert and N. Lynch, “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services,” ACM SIGACT News, vol. 33, no. 2, pp. 51-59,2002.
[6] D. J. Abadi, “Consistency tradeoffs in modern distributed database system design: CAP is only part of the story,”Computer, vol. 45, no. 2, pp. 37-42, 2012.
[7] M. Stonebraker, N. Hachem, and P. Helland, “The end of an architectural era: (It's time for a complete rewrite),” in Proc.of the 33rd Int. Conf. on Very Large Data Bases, Vienna,2007, pp. 1150-1160.
[8] J. Rao, C. Zhang, G. Lohman, et al., “Automating physical database design in a parallel database,” in Proc. of Int. Conf.on Management of Data and Symposium on Principles Database and Systems, Madison, 2002, pp. 558-569.
[9] D. C. Zilio, J. Rao, S. Lightstone, et al., “DB2 design advisor: integrated automatic physical database design,” in Proc. of the 30th Int. Conf. on Very Large Data Bases,Toronto, 2004, pp. 1087-1097.
[10] S. Agrawal, V. Narasayya, and B. Yang, “Integrating vertical and horizontal partitioning into automated physical database design,” in Proc. of the ACM SIGMOD Int. Conf. on Management of Data, Paris, 2004, pp. 359-370.
[11] A. Pavlo, C. Curino, and S. Zdonik, “Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems,” in Proc. of the ACM SIGMOD Int. Conf. on Management of Data, Scottsdale, 2012, pp. 61-72.
[12] A. Thomson, T. Diamond, S.-C. Weng, et al., “Fast distributed transactions for partitioned database systems,” in Proc. of the ACM SIGMOD Int. Conf. on Management of Data, Scottsdale, 2012, pp. 1-12.
[13] A. L. Tatarowicz, C. Curino, E. P. C. Jones, et al., “Lookup tables: Fine-grained partitioning for distributed databases,”in Proc. of the 28th IEEE Int. Conf. on Data Engineering,Washington, 2012, pp. 102-113.
[14] P. M. G. Apers, “Data allocation in distributed database systems,” ACM Trans. on Database System, vol. 13, no. 3,pp. 263-304, 1998.
[15] A. L. Corcoran and J. Hale, “A genetic algorithm for fragment allocation in a distributed database systems,” in Proc. of 1994 ACM symposium on Applied computing,Phoenix, 1994, pp. 247-250.
[16] S. Menon, “Allocating fragments in distributed databases,”IEEE Trans. on Parallel and Distributed Systems, vol. 16,no. 7, pp. 577-585, 2005.
 Journal of Electronic Science and Technology2013年2期
Journal of Electronic Science and Technology2013年2期
- Journal of Electronic Science and Technology的其它文章
- Call for Papers Journal of Electronic Science and Technology Special Section on Terahertz Technology and Application
- JEST COPYRIGHT FORM
- ID-Based User Authentication Scheme for Cloud Computing
- Interpurchase Time of Customer Behavior in Cloud Computing
- A Genetic Algorithm Based Approach for Campus Equipment Management System in Cloud Server
- Toward Cloud-Based Parking Facility Management System: A Preliminary Study